Download
The dataset is organized in 4 folders:
- Data The Data folder contains files general information regarding our dataset. Here you can find information regarding user ratings, the titles of the movies we used and preferred download method etc. The "rating.txt" file gives general information regarding the way the movie ratings were obtained, along with a download link for the corresponding movie ratings files. The "movie_description.csv" file has general information regarding the movie files we used: movieId (an id shared across the system, for identifying movies trailers and their corresponding features and ratings), title (the title of the movie trailer) and finally YTId (the youtube link for each individual movie trailer). The "itemids_splitted_5foldCV" contains information regarding the 5 folds we used in out experiments (see Benchmark), including the train and test split we created for each of them, thus creating 10 files - 5 folds/files for train, 5 folds/files. Each of these files contains the movieId and userId information that can be further used to replicate our experiments exactly.
- Metadata descriptors The Metadata descriptors folder contains three CSV files associated with each of the three provided features: genre features, tag features and year of production.
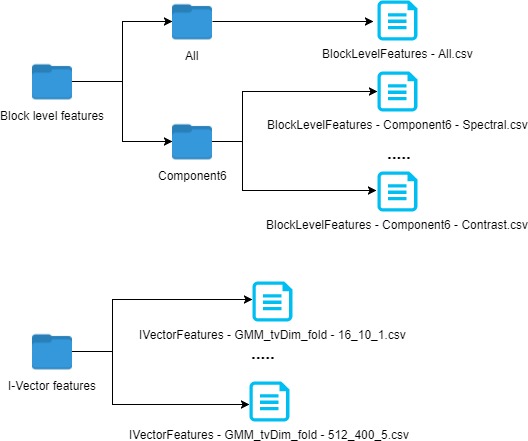
- Audio descriptors The Audio descriptors folder contains two sub-folders: Block level features and i-vector features. While the BLF data includes the raw features of the 6 subcomponents and similarities computed thereon, the i-vector features include different parameters for the Gaussian mixture model (GMM), total variability dimension (tvDim) and the folds information used for creating the feature vector. The BLF folder has two subfolders: "All" and "Component6"; the former contains the similarities computed using all 6 subcomponents, the latter contains the raw feature vectors of the subcomponents in separate CSV files. The i-vector features folder contains individual CSV files for each of the possible combinations of the three parameters, fold, gmm and tvDim.
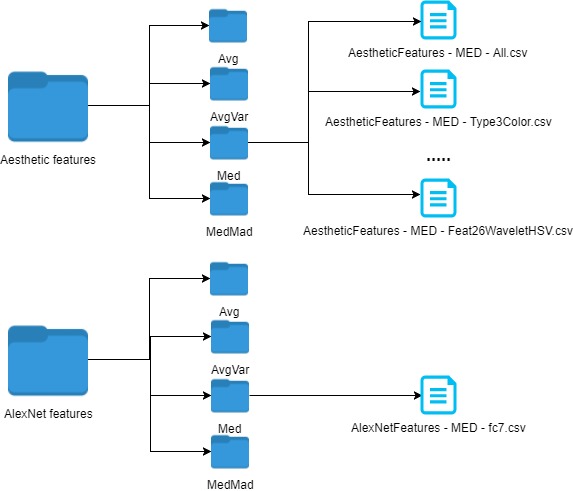
- Visual descriptors The Visual descriptors folder contains two subfolders: Aesthetic features and AlexNet features, each of them including different aggregation and fusion schemes for the two types of visual features. These two features are aggregated by using four basic statistical methods, each included in a different subfolder, that compute a video-level feature vector from frame-level vectors by using: average value across all frames (denoted "Avg"), average value and variance ("AvgVar"), median values ("Med") and finally median and median average distribution ("MedMad"). Each of the four aggregation subfolders of the Aesthetic features folder contains CSV files for three types of fusion methods: early fusion of all the components (denoted All), early fusion of components according to their type (color based components denoted Type3Color, object based components - Type3Object and texture - Type3Texture) and finally each of the 26 individual component with no early fusion scheme (example: the colorfulness component denoted Feat26Colorfulness), therefore generating a total of 30 files in each subfolder. Regarding the AlexNet features, In our context, we use the extracted output values of the fc7 layer, and therefore no supplementary early fusion scheme is required or possible, and therefore only one CSV file is present inside each of the four aggregation folders.